SQLite in 2018: Ein SQL-Dialekt am Stand der Technik
SQLite ist eine unterschätzte Datenbank. Manche glauben sogar, SQLite wäre keine „richtige“ Datenbank und nicht für den Produktionsbetrieb geeignet. Tatsächlich ist SQLite eine sehr solide Datenbank, die auch Terabytes an Daten verwalten kann. Lediglich die Netzwerkschicht fehlt.
SQLite ist nämlich „nur“ eine Bibliothek – kein Server. Einerseits scheidet SQLite damit für viele Anwendungen aus, andererseits ist es dadurch für viele andere Anwendungen gerade richtig. Offenbar sind das sogar so viele Anwendungen, das SQLite – laut eigener Angabe – die am öftesten installierte und genutzte Datenbank ist. Das ist vermutlich nur möglich, weil SQLite lizenzfrei ist („public domain“). Wenn man also SQL nutzen möchte, um Daten in einer Datei zu speichern, ist SQLite die erste Wahl.
Der SQL-Dialekt von SQLite braucht den Vergleich auch nicht zu fürchten. Die With -Klausel wurde in SQLite zum Beispiel vier Jahre früher als in MySQL eingeführt. Zuletzt wurde SQLite um Window-Funktionen erweitert – nur fünf Monate nachdem MySQL Window-Funktionen eingeführt hat.
Dieser Artikel widmet sich den SQL-Erweiterungen, die SQLite im Jahr 2018 erfahren hat. Das sind also die neuen SQL-Funktionen der Versionen 3.22.0 bis 3.26.0.
Inhalt:
Boolean-Literale und Tests
Beim Datentypen Boolean mogelt SQLite: Boolean wird zwar als Typennamen akzeptiert, ist aber letztendlich nur ein Alias für Integer (analog zu MySQL). Die Wahrheitswerte true und false werden – wie in C – durch die Werte 1 und 0 repräsentiert.
Ab Version 3.23.0 kennt SQLite die Schlüsselworte true und false als Synonyme für die Werte 1 und 0 und unterstützt den Test is [not] true|false . Das Schlüsselwort unknown wird jedoch generell nicht unterstützt. Man kann stattdessen – wie zuvor – null verwenden, da die Boolean-Werte unknown und null ununterscheidbar sind.
Die Literale true und false können die Lesbarkeit von Values - und Set -Klauseln in Insert - und Update -Anweisungen deutlich erhöhen.
Der is [not] true|false -Test ist nützlich, weil er etwas anderes bedeutet, als die entsprechenden Vergleichsoperatoren:
WHERE c <> FALSE
bedeutet etwas anderes als
WHERE c IS NOT FALSE
Wenn c den Null-Wert hat, ist das Ergebnis der Bedingung c <> false unknown. Da die Where -Klausel nur true akzeptiert – false und unknown werden abgelehnt – scheinen solche Zeilen nicht im Ergebnis auf.
Im Gegensatz dazu ist das Ergebnis von c is not false auch dann true, wenn c den Null-Wert hat. Die zweite Where -Klausel akzeptiert also auch Zeilen, in denen c den Null-Wert hat.
Eine andere Möglichkeit, dieselben Zeilen auszuwählen, ist, den Null-Fall separat zu akzeptieren.
WHERE c <> FALSE OR c IS NULL
Diese Variante ist natürlich länger und auch etwas redundant ( c wird zweimal genannt). Letztendlich kann der Is not false -Test also dazu verwendet werden, solche Or … is null -Konstruktionen zu vermeiden. Mehr dazu in „Binäre Entscheidungen auf Basis dreiwertiger Ergebnisse“.
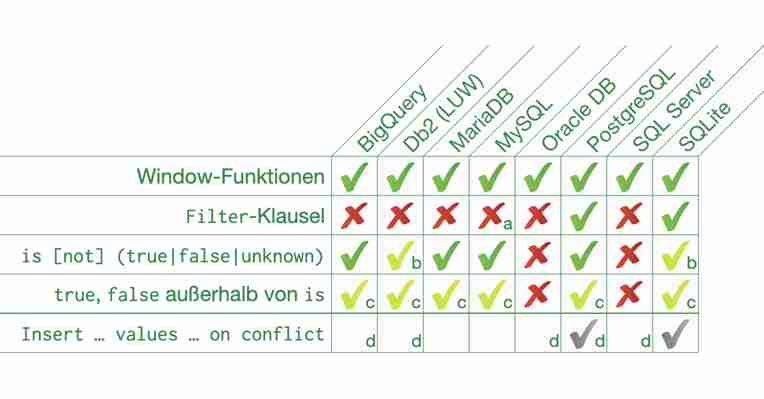
Die Unterstützung der Boolean Literale und des Boolean Tests in SQLite ist auf ähnlichem Niveau wie in anderen Open-Source-Datenbanken. Einzig die Unterstützung für is [not] unknown fehlt bei SQLite im Vergleich zu anderen Datenbanken. Interessanterweise sind diese Boolean-Funktionen bei den unten gezeigten kommerziellen Produkten generell nicht verfügbar.
Window-Funktionen
SQLite 3.25.0 führt Window-Funktionen ein. Wer Window-Funktionen kennt, weiß, dass das eine große Sache ist. Wer Window-Funktionen nicht kennt, sollte sie kennenlernen! Dieser Artikel ist nicht der richtige Ort, um Window-Funktionen zu erklären. Ich übertreibe aber nicht, wenn ich sage, dass Window-Funktionen die wichtigste „moderne SQL“-Funktion überhaupt sind.
Der Funktionsumfang der Over -Klausel ist bei SQLite ziemlich nahe an dem anderer Datenbanken. Der einzig nennenswerte Rückstand ist, dass Range -Rahmen (frame) keine Numerischen- oder Intervall-Distanzen unterstützen (nur current row und unbounded preceding|following ). Das ist dieselbe Einschränkung, die auch SQL Server hat, und PostgreSQL hatte, als Window-Funktionen in SQLite eingeführt wurden. Mit PostgreSQL 11 wurde diese Beschränkung in der Zwischenzeit aufgehoben.
Die Menge der angebotenen Window-Funktionen ist bei SQLite ebenfalls am aktuellen Stand anderer Datenbanken. Die nennenswerten Lücken ( distinct in Aggregatfunktionen, width_bucket , respect|ignore nulls und from first|last ) gibt es auch in einigen anderen Produkten.
Filter -Klausel
Obwohl die Filter -Klausel nur eine syntaktische Schönheitsmaßname ist – mit einem Case -Ausdruck kann man dasselbe Ergebnis erzielen – denke ich, dass die Filter -Klausel essenziell ist, weil sie das Lernen maßgeblich erleichtert.
Betrachte dazu die folgenden Select -Klauseln. Welche ist einfacher zu verstehen?
SELECT SUM(umsatz) gesamt_umsatz , SUM(CASE WHEN produkt = 1 THEN umsatz END ) prod1_umsatz ...
vs.
SELECT SUM(umsatz) gesamt_umsatz , SUM(umsatz) FILTER(WHERE produkt = 1) prod1_umsatz ...
Dieses Beispiel fasst zusammen, was die Filter -Klausel macht: Sie ist ein Zusatz zu Aggregatfunktionen, der dafür sorgt, dass nur die Werte bestimmter Zeilen aggregiert werden. Die Pivot-Technik ist der häufigste Anwendungsfall der Filter -Klausel. Dazu zählt auch die Transformation von Attributen im Entity-Attribute-Value (EAV) Modell in Spalten.
SQLite 3.25.0 führ die Filter -Klausel für Aggregatfunktionen ein, wenn sie die Over -Klausel verwenden — also nicht mit group by . Leider bedeutet das, dass man die Filter -Klausel für die oben genannten Anwendungsfälle in SQLite noch nicht nutzen kann. Man muss dafür also nach wie vor auf Case -Ausdrücke zurückgreifen. Ich hoffe, dass sich das bald ändern wird.
BigQuery Db2 (LUW) MariaDB MySQL Oracle DB PostgreSQL SQL Server SQLite filter mit group by filter mit over
Insert … on conflict („Upsert“)
Mit SQLite 3.24.0 wurde das sogenannte „Upsert“ eingeführt: ein Insert -Statement, das die Behandlung von Primärschlüssel- und Unqiue-Constraint-Verletzungen erlaubt. Damit kann man diese Fehler ignorieren ( on conflict … do nothing ) oder ein Update auf die bereits existierende Zeile ausführen ( on conflict … do update … ).
Upsert ist eine proprietäre SQL-Erweiterung – d. h. es kommt nicht aus dem SQL-Standard und ist daher in der Matrix unten Grau gehalten. SQLite verwendet jedoch dieselbe Syntax wie PostgreSQL. Der SQL-Standard sieht für diese Anforderung das Merge -Statement vor.
Anders als PostgreSQL hat SQLite aufgrund einer syntaktischen Mehrdeutigkeit ein Problem mit der folgenden Anweisung.
INSERT INTO ziel SELECT * FROM quelle ON CONFLICT (id) DO UPDATE SET wert =
Laut Dokumentation liegt das Problem darin, dass der Parser nicht weiß, ob das Token on zu einem Join gehört, oder eine Upsert-Klausel einleitet. Diese Mehrdeutigkeit kann man vermeiden, indem man der Abfrage eine weitere Klausel hinzufügt – z. B. where true .
INSERT INTO target SELECT * FROM source WHERE true ON CONFLICT (id) DO UPDATE SET val = excluded.val
Rename Column
Eine weitere proprietäre Erweiterung, die SQLite eingeführt hat, ist das Umbenennen von Spalten in Basistabellen. Der SQL-Standard bietet keine Funktion dafür an.
SQLite folgt der Syntax, die auch von vielen anderen Produkten angeboten wird.
ALTER TABLE … RENAME COLUMN … TO …
Andere Neuerungen
Neben den SQL-Änderungen gab es in 2018 natürlich auch Erweiterungen der API. Ein Blick in die Neuerungen von SQLite lohnt sich.
Als Nächstes auf
Der nächste Artikel über PostgreSQL 11 ist bereits in Arbeit. Folge via Twitter, E-Mail oder RSS.
Wenn Du mehr über modernes SQL lernen willst, solltest du dir meine Schulung im Mai ansehen. Neben den oben erwähnten Window-Funktionen behandle ich dort auch Rekursionen, Indizierung und verfestige die Grundlagen. Schulungsgrundlage ist der aktuelle Entwurf meines nächsten Buches. Schulung jetzt ansehen!
PHP und SQLite3 für Webseiten
SQLite – Datenbank in einer Datei
SQLite nimmt eine Datei und nutzt sie als Datenbank. SQLite 3.6 war in den meisten PHP-Installation ab PHP 5.3 schon vertreten, im PHP 7 sitzt SQLite 3.30 (2019-10-11) oder neuer. SQLite ist der zuverlässige Langzeitspeicher in allen Mobilgeräten und damit die meist genutzte Datenbank.
PHP stellt zwei Schnittstellen für SQLite3 bereit:
Natives SQLite3
Das native PHP-SQLite3-Interface ist stark an SQLite3 in C ausgerichtet. Allerdings ist PHP SQLite3 nicht die vollständige Umsetzung von SQLite3 in C, unterstützt Exceptions nicht vollständig und die Fehlerbehandlung ist spartanisch.
PDO – PHP Data Objects
PDO ist eine normalisierte Schnittstelle zu Datenbanken auf verschiedenen Plattformen und stellt in den meisten Fällen das bevorzugte Interface zu SQLite3 dar.
Neues über Datenbanken: SQL-Nachfolger, Cloud-Krieg, Volcano-Modell
Neues über Datenbanken — Herbst 2019

Zweimal im Jahr lasse ich die Nachrichten der letzten sechs Monate Revue passieren und verpacke die interessantesten Neuigkeiten in eine kurze Geschichte. Es ist wieder so weit. Abonniere den Newsletter, um künftige Ausgaben zu erhalten.
Der SQL-Nachfolger?
In der letzten Ausgabe habe ich berichtet, wie der SQL-Standard momentan um Funktionen zur Abfrage von Graphen und später vielleicht sogar um Streamprocessing erweitert wird. Diesmal möchte ich den Blick auf einen anderen Vorstoß werfen: eine neue Sprache, die SQL vielleicht sogar ablösen könnte.
Im August 2019 verkündete Amazon, mit PartiQL (gesprochen: Partikl) „eine Abfragesprache für alle Daten“ erfunden zu haben. Bei genauerer Betrachtung ist PartiQL aber eher ein Rebranding von SQL++ als eine neue Erfindung.
Die Geschichte beginnt in 2014 mit der Veröffentlichung des Papers zu SQL++. In der ursprünglichen Version dieses Papers verglich man die Möglichkeiten verschiedener Abfragesprachen im Bereich von SQL-on-Hadoop, NoSQL und NewSQL. Als Mittel zum Zweck wurde SQL++ als hypothetische Über-Sprache erschaffen, die alle Funktionen der untersuchten Sprachen abdeckt. Der Vergleich selbst ist dann im Wesentlichen eine Diskussion, wie die SQL++-Funktionen von den untersuchten Sprachen unterstützt werden.
Erst in späteren Versionen des Papers rückt SQL++ selbst ins Zentrum. Denn einige Hersteller bekundeten ihr Interesse an der Umsetzung dieser Sprache. Einer davon war Couchbase, wo man danach strebte, die eigene Sprache N1QL an SQL++ anzugleichen. In der Zwischenzeit hat Couchbase diesen Plan mit N1QL for Analytics in die Tat umgesetzt. Das ist übrigens nicht zu verwechseln mit N1QL for Query, welches vormals nur N1QL genannt wurde, und nicht SQL++-kompatibel ist. Relevanter XKCD-Comic.
Gleichzeitig hat einer der SQL++-Autoren bei Amazon daran gearbeitet, diese Über-Sprache unter dem Namen PartiQL als Norm zu etablieren. Die Neuerungen gegenüber SQL++ betreffen dabei weniger die Sprache selbst, als das Drumherum. So gibt es für PartiQL zum Beispiel eine (unvollständige) Open-Source-Referenzimplementierung.
Die Frage, ob sich PartiQL tatsächlich als die eine Sprache für alle Daten durchsetzen wird, kann man einfach mit „daran sind schon andere gescheitert“ abtun. PartiQL ist nämlich nicht ganz so naiv wie andere Vorstöße in diese Richtung. Ein wichtiger Aspekt ist, dass PartiQL SQL-kompatibel ist. Auch wenn PartiQL aktuell nur einen kleinen Teil von SQL-92 abdeckt, sind viele gültige SQL-Abfragen gleichzeitig auch gültige PartiQL-Abfragen. Das erleichtert sowohl das Erlernen der neuen Sprache als auch die Migration bestehender Projekte. Außerdem kann PartiQL nicht ohne weiteres in den SQL-Standard integriert werden, wie es bei den eingangs genannten Beispielen angestrebt wird. Der essenzielle Unterschied zwischen PartiQL und SQL – dynamische vs. statische Typisierung – geht nämlich an die Grundfeste von SQL. Die allgemeine Umstellung von SQL auf eine dynamische Typisierung, wie sie PartiQL vorsieht, ist für mich unvorstellbar. Denkbar wären „dynamische Typen“, auf die wie SQL-Arrays und SQL-Objekte zugegriffen wird, aber eben ohne statische Typenprüfung. Eine Art begrenzte dynamische Typisierung. Das könnte das Beste aus beiden Welten sein.
Cloud Wars: Ungewöhnlicher Strafzoll auf den Umstieg in die Cloud
In einer aktuellen Analyse prognostiziert Gartner 17 % Umsatzwachstum für öffentliche Cloud-Lösungen. Kein Wunder, dass Softwarehersteller bemüht sind, ihren Kunden den Umstieg in die Cloud möglichst einfach zu machen. Da ist es durchaus überraschend, dass Microsoft kürzlich eine neue Umstiegshürde einführte.
In eigener Sache: Schulungstermin 23.-27. März in Wien Seit SQL-92 hat sich einiges getan. Mein 5-tägiges Training ist das Update für Entwickler. Nur noch bis Weihnachten: € 500,00 Frühbucherrabatt. Alle Details und die Anmeldung gibt’s hier!
Das wichtigste vorweg: Diese neue Hürde betrifft nur ein sehr spezielles Szenario. Es geht um die Verwendung dedizierter Hardware in den Cloud-Umgebungen von Alibaba, Amazon, Google und auch Microsoft selbst. Für dieses Szenario können On-Premises-Lizenzen, die ab Oktober 2019 gekauft wurden, nicht mehr ohne Weiteres im Rahmen eines „Bring Your Own-License“-Setups in der Cloud weiterverwendet werden. Neue Lizenzen erlauben das nur, wenn auch Software Assurance mitgekauft wird, was die jährlichen Kosten um 25 % erhöht.
Technologie und Wissenschaft
Endlich unterstützt MySQL den Hash-Join-Algorithmus. Andere Produkte verwenden diesen Algorithmus, der insbesondere bei großen Datenmengen vorteilhaft sein kann, schon seit Jahrzehnten. Ich möchte an dieser Stelle aber nicht auf den Hash-Join-Algorithmus eingehen, sondern vielmehr erklären, warum er bei MySQL so spät kam.
Die Geschichte beginnt in den 1980er Jahren, lange vor der ersten MySQL-Version. Am Ende dieser Dekade wurde nämlich das sogenannte Volcano-Modell zur Ausführung von Abfragen vorgestellt (Paper). Die Schlüsselidee war, dass alle Operationen ein gemeinsames Interface haben, sodass alle Operationen beliebig kombiniert und wie Lego-Steine zu einem größeren Ganzen zusammengesetzt werden können. Das System hat sich durchgesetzt und ist vielen Datenbanknutzern als Ausführungsplan bekannt.
MySQL – und damit auch MariaDB – setzte das Volcano-Modell anfangs allerdings nicht um. Stattdessen schlichen sich Annahmen in den Code ein, wie verschiedene Operationen zusammenspielen können. Die Flexibilität war stark eingeschränkt. Weitere Details sind in Work-List Item 11785 dokumentiert. Letztendlich hat man sich bei Oracle aber entschieden, das Volcano-Modell auch für MySQL umzusetzen. Mit der Version 8.0.18 wurde die neue Implementierung im Oktober freigegeben.
Die Einführung neuer Operationen ist damit relativ einfach geworden. Der Hash-Join-Algorithmus ist lediglich ein Beispiel. Ein anderes ist das EXPLAIN ANALYZE -Kommando, dass das gemeinsame Interface aller Operationen für Performancemessungen nutzt. Dabei hat man sich die Syntax und das Ausgabeformat von PostgreSQL abgeschaut.
Eine andere, unabhängige Veröffentlichung rund um das Volcano-Modell gab es kürzlich von CockroachDB: Dort hat man das Interface zwischen den Operationen des Volcano-Modells so erweitert, dass mehrere Zeilen auf einmal weitergereicht werden können. Nachdem die Operationen angepasst wurden, um das erweiterte Interface effizient zu nutzen, wurden manche Abfragen um den Faktor vier schneller. Eine ähnliche Erweiterung gab es übrigens bei SQL Server 2019: Dort wird dieses Vorgehen Batch-Mode genannt und wurde ursprünglich für den spaltenorientierten Speicher Columnstore eingeführt. Nun steht dieser Ausführungsmodus auch beim Zugriff auf normale, zeilenorientierte Tabellen zur Verfügung.
Zuletzt möchte ich noch ein aktuelles Paper erwähnen: APOLLO: Automatic Detection and Diagnosis of Performance Regressions in Database Systems. Dabei geht es darum, Performanceverschlechterungen zwischen Datenbankversionen automatisch zu erkennen. Nachdem man den Algorithmus zwei Monate laufen ließ, hatte er insgesamt 11 Bugs in SQLite und PostgreSQL gefunden. Zwei davon sind bereits korrigiert, fünf weitere von dem jeweiligen Hersteller bestätigt.
Neue Versionen
Eine genauere Analyse der neuen SQL-Funktionen dieser Releases erscheint in den nächsten Monaten auf (Twitter, Email, RSS).
Neue Artikel, Folien und Aufzeichnungen
Via Twitter, in aller Kürze (folge mir auf Twitter)
SQL Renaissance Ambassador
Als SQL Renaissance Ambassador ist es meine Mission, Entwickler auf die Evolution von SQL im 21. Jahrhundert aufmerksam zu machen. Mein Buch „SQL Performance Explained“ ist in fünf Sprachen erschienen und kann online kostenlos auf gelesen werden. Mein nächstes Buch kann bereits während des Entstehens online gelesen werden Allen SQL-interessierten Unternehmen und Entwicklern stehe ich als Trainer, Sprecher und Berater zur Verfügung. Mehr Infos dazu auf winand.at.